Cross-Lingual Contrastive Learning for Fine-Grained Entity Typing for Low-Resource Languages
论文内容简介:
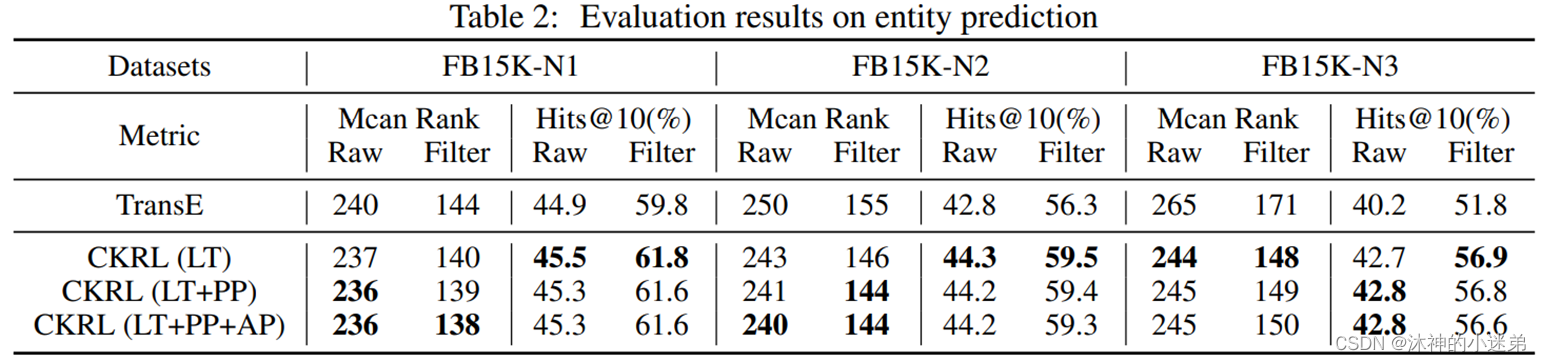
细粒度实体类型分析(Fine-grained entity typing,简称FGET)旨在将实体命名事件划分为细粒度的实体类型,这对于实体相关的NLP任务具有重要意义。
提出问题:FGET面临的一个关键挑战是资源匮乏问题—复杂的实体类型层次结构使得人工标记数据变得困难。特别是对于英语以外的其他语言(如中文),人工标注数据极其稀缺。
本文解决方案:使用多语言预训练语言模型(PLMs)作为骨干,将高资源语言(如英语)的类型知识迁移到低资源语言(如汉语)。此外,引入面向实体对的启发式规则和机器翻译来获取跨语言远程监督数据,并在远程监督数据上应用跨语言对比学习增 强骨干PLMs。
实验结果:没有任何特定于语言的人工标记数据,也可以轻松地学习到有效的低资源语言FGET模型。
难点:
(1)不同语言具有截然不同的模式,同时理解高资源语言和低资源语言的语义是一项具有挑战性的工作。
(2)只有少量的低资源语言实例,且没有平行数据,在不同语言之间架起知识迁移的桥梁也很困难。
解决思路:
(1)多语言预训练语言模型(PLMs)作为骨干。M-BERT等多语言PLMs在大规模多语言语料上进行预训练,以其为骨干可以很好地将不同语言的数据编码到相同的语义空间。
(2)应用启发式规则:设计了多个面向实体对的启发式规则用于远程监督,利用实体对之间的潜在关系自动标注实体类型。利用机器翻译对自动标注的数据进行翻译,建立高资源语言和低资源语言之间的联系。
(3)采用对比学习方法学习跨语言自动标注类型之间的相似性,而不是使用伪标签学习分类器,这可以增强类型识别能力并减少自动标注数据的副作用。
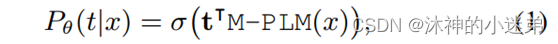
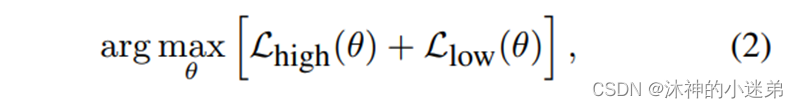
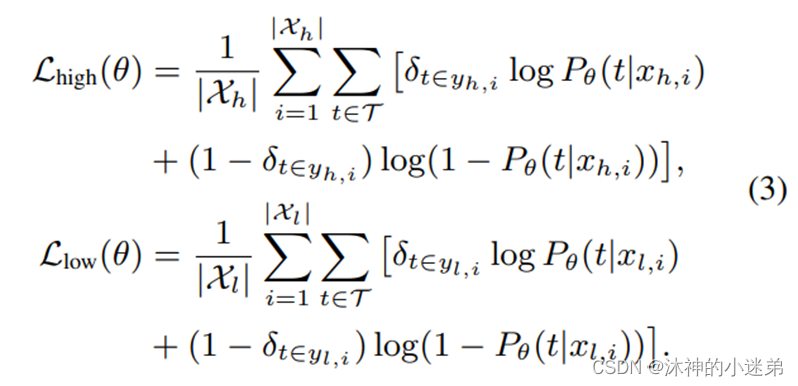
利用远程监督和机器翻译的优势,我们可以极大地扩展数据集。
为了使 FGET 模型更多地关注文本上下文而不是仅仅关注实体名称,我们使用[MASK]以0.5的概率屏蔽实体。
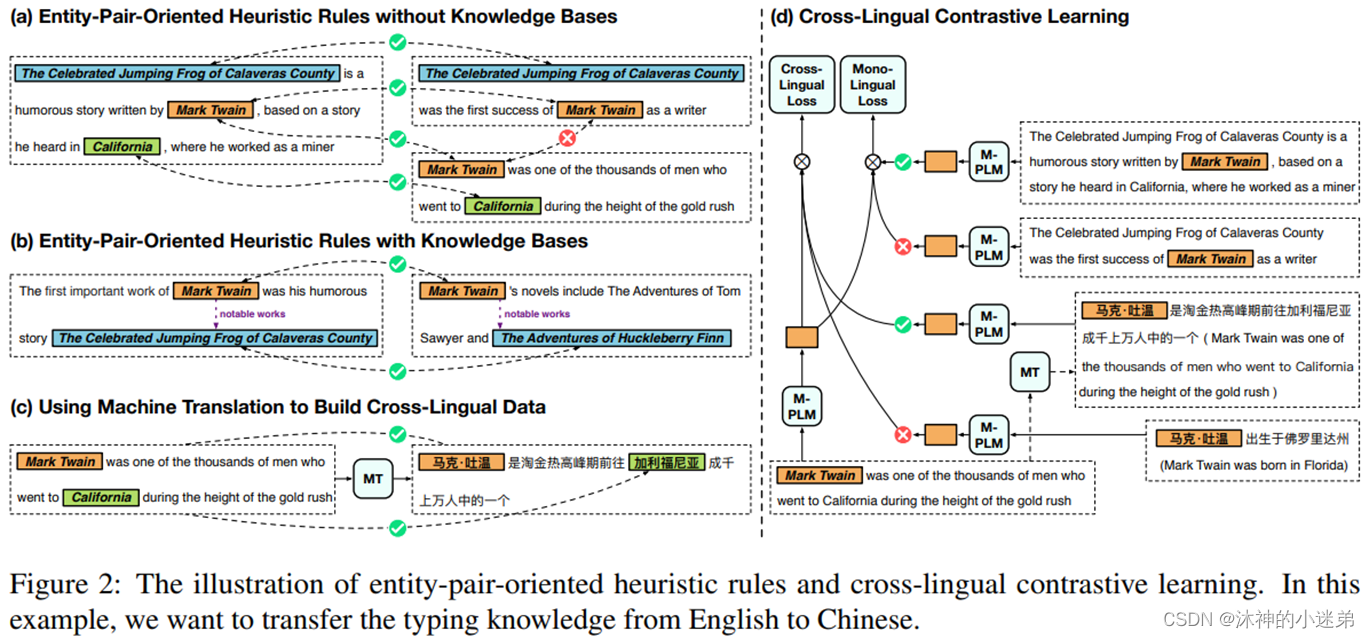
(1)没有知识库的规则。
(2)带有知识库的规则。
(3)利用机器翻译构建跨语言数据
论文提出了面向实体对的启发式规则(figure d),以减少噪声对数据的自动标注。不再标注特定的实体类型,而是标注两次提及的实体是否具有相似的类型。

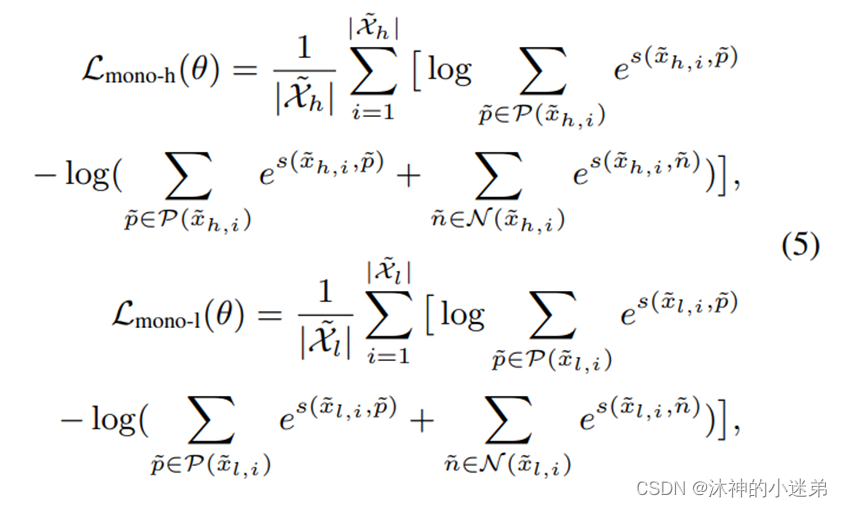

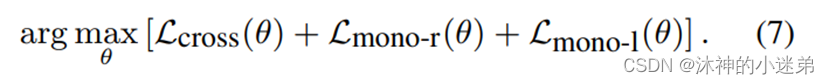
整个学习过程分为两个阶段:预训练和微调
预训练阶段使用 Eq.(7) 来优化远程监督数据上的参数。考虑到计算效率,我们每次采样一批样本进行对比学习,然后为这批样本中的每一个样本采样多个正样本。
微调阶段使用 Eq.(2) 来微调人类标记数据上的参数以学习FGET 的分类器。
两个实体相关数据集Open-Entity和Few-NERD在低资源(few-shot & zero-shot)和全量数据集下进行实验。
Open-Entity包括 9 种一般类型和 121 种细粒度类型。 Open-Entity中的每个示例可能对应多个实体类型。
Few-NERD 包括 8 种一般类型和 66 种细粒度类型。
在实验中,我们需要模型预测句子中提到的每个实体的一般类型和细粒度类型。
选择英语作为高资源语言,汉语作为低资源语言。
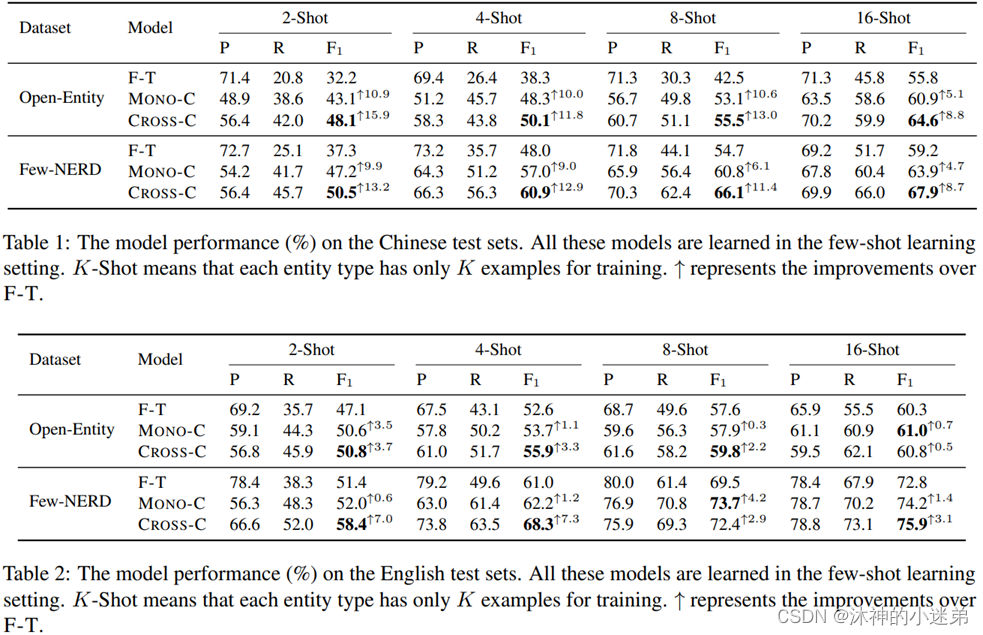
“F-T”来表示直接使用英语人类标签数据来微调。“MONO-C”表示仅使用单语言对比学习目标进行预训练,然后使用英语的标记数据微调预训练参数。
效果:
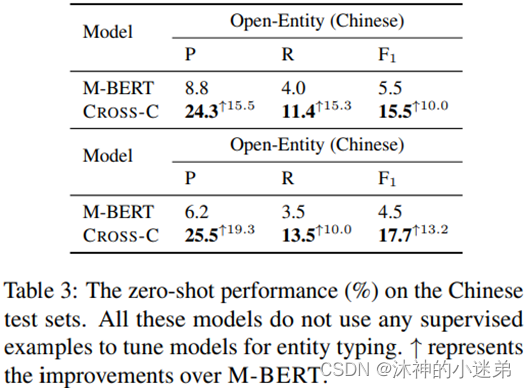
(1)所有的方法都可以在中文测试集上获得很好的实体分类结果,而无需使用任何中文人工标记样本作为训练模型。
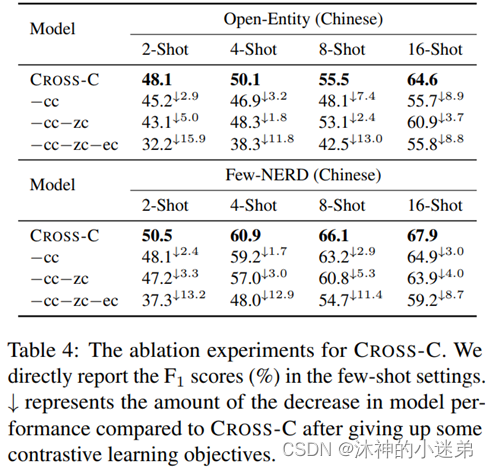
(2)使用远程监督数据进行对比学习可以显著提高骨干PLMs的分类能力。
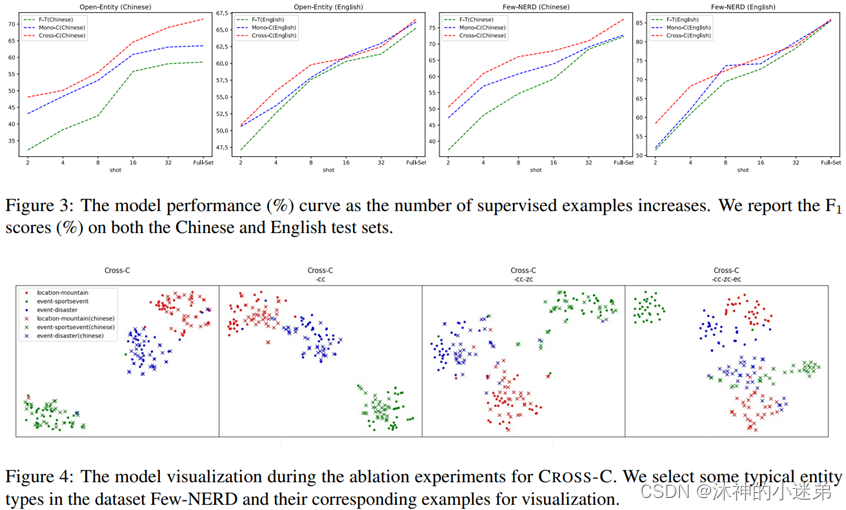
(3)与单语言对比学习相比,我们的跨语言对比学习能够更好地促进类型知识从高资源语言到低资源语言的迁移。
本文虽然有挂代码在github,但是缺少数据集无法复现。
https://github.com/thunlp/CrossET